1、使用YOLOV8识别图片
下载一张图片到工作目录中
wget -O bus.jpg https://ultralytics.com/images/bus.jpg

使用yolo的预测/推理指令对图片中的事物进行检测
yolo predict model=yolov8n.pt source=bus.jpg imgsz=640 conf=0.25
运行指令后会下载模型参数数据.pt文件。
然后会进行检测,在目录下会有runs目录里存放了标定后的图片
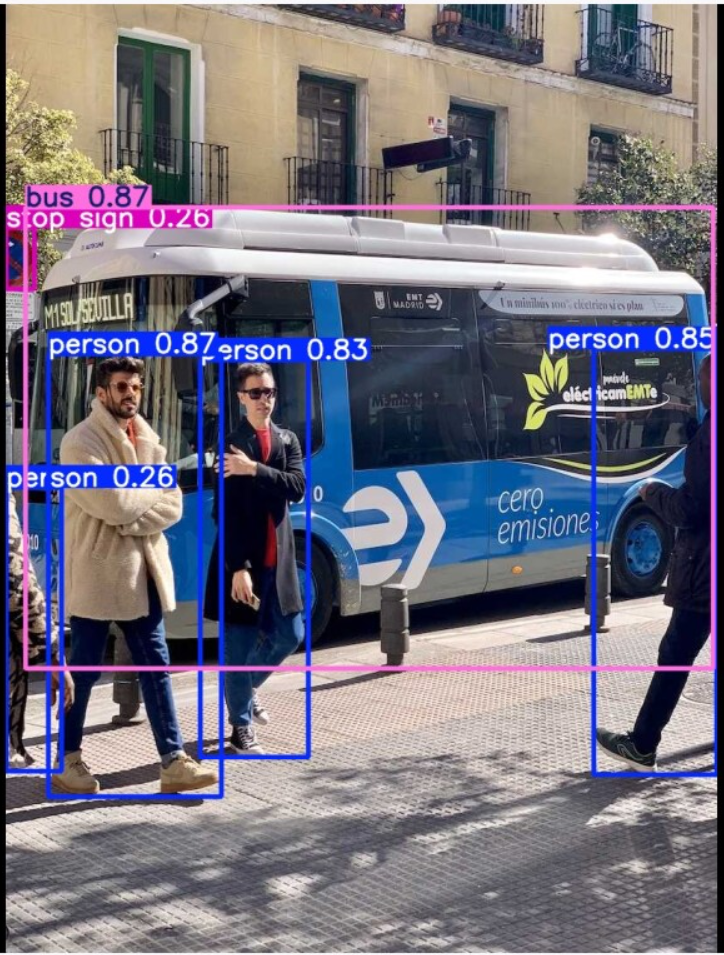
一条指令就完成了图片中人、公交的识别。
1) yolo predict 是什么?
yolo:Ultralytics 提供的命令行工具入口(安装 ultralytics 后就有)。
predict:执行“推理/预测”任务(对输入做检测、分割、分类、姿态等任务中的推理)。
在用的 yolov8n.pt 里,它是一个目标检测模型,所以 predict 就会输出框+类别+置信度。
2) model=yolov8n.pt
指定要用的模型文件(权重):yolov8n.pt:
v8 表示 YOLOv8 系列
n 表示 nano(最小、最快、精度相对低一点)
.pt 表示 PyTorch 权重格式
第一次跑的时候它通常会自动下载这个模型到本机缓存(如果你本地还没有)。
3) source=bus.jpg
指定输入来源(数据源):
这里是一个图片文件 bus.jpg
source 也可以是:
摄像头:source=0
视频文件:source=video.mp4
文件夹:source=images/
RTSP 流:source=rtsp://...
这一步就是“对单张图片做检测”。
4) imgsz=640
指定推理时模型使用的输入尺寸(image size):640 表示把输入图像缩放/填充到 640×640 再送进网络
影响:
越大:通常更准(小目标更容易检测到),但更慢
越小:更快,但可能漏检小物体
注意:原图可能不是正方形,Ultralytics 会做“等比缩放 + padding(letterbox)”来适配 640×640,所以你看到的框仍然会映射回原图尺寸。
5) conf=0.25
置信度阈值(confidence threshold):
模型对每个候选框都会给一个置信度分数(01)
conf=0.25 的意思是:只保留置信度 ≥ 0.25 的检测结果
影响:
阈值 高:框更少,误检更少,但可能漏检
阈值 低:框更多,召回更高,但可能误检多
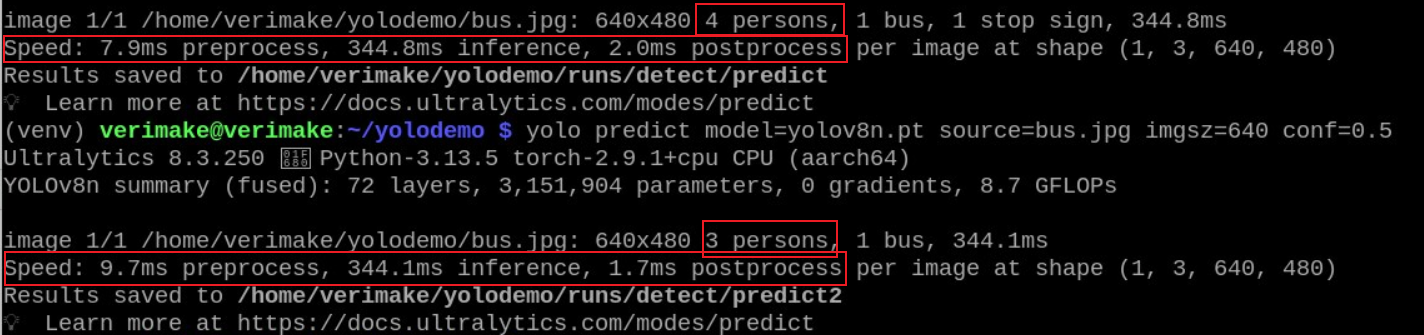
本次检测中我们会发现左下角有一个识别为人的框置信度只有0.26,通过我们仔细观察后面其实没有人,所以我们可以调高置信度到0.5,此时左下角的那个0.26的person框就没有了。运行一遍
yolo predict model=yolov8n.pt source=bus.jpg imgsz=640 conf=0.5

两次识别的过程以及打印信息中我们可以看到相应的处理处理结果和时间。
对于图片中识别的物品信息如何导出或者记录呢?可以编写下面的代码对于识别的物品单独输出信息,而不是在图片上直接标注,我们可以提取相关信息用于自主使用。
from collections import Counter
from ultralytics import YOLO
# -----------------------
# 1) 配置:输入、模型、阈值、推理尺寸
# -----------------------
IMG = "bus.jpg" # 输入图片路径(相对路径或绝对路径都可以)
MODEL = "yolov8n.pt" # 使用的 YOLO 模型权重(这里是 COCO 预训练的 v8 nano)
CONF = 0.5 # 置信度阈值:低于这个分数的检测结果会被过滤掉
IMGSZ = 640 # 推理时输入尺寸:图片会被缩放/填充到 IMGSZ×IMGSZ
def main():
# -----------------------
# 2) 加载模型
# -----------------------
model = YOLO(MODEL)
# -----------------------
# 3) 做一次推理(对单张图片)
# model.predict 返回一个列表 results:
# - 如果 source 是单张图片,results 通常只有 1 个元素
# - 如果 source 是文件夹/视频/多张图片,则 results 会有多个元素
# -----------------------
results = model.predict(
source=IMG, # 输入源:图片文件
imgsz=IMGSZ, # 推理输入尺寸
conf=CONF, # 置信度阈值
verbose=False # 关闭冗长日志输出
)
# 取出单张图片对应的推理结果
r = results[0]
# -----------------------
# 4) 类别映射表:{class_id: class_name}
# 例如:{0:'person', 1:'bicycle', ...}
# -----------------------
names = r.names
# -----------------------
# 5) 检测框集合
# r.boxes 里面包含所有检测到的目标框(可能是 0 个)
# 每个框对象 b 通常有:
# - b.cls: 类别 id(tensor)
# - b.conf: 置信度(tensor)
# - b.xyxy: (x1,y1,x2,y2) 左上+右下像素坐标(tensor)
# - b.xywh: (cx,cy,w,h) 中心点+宽高像素坐标(tensor)
# -----------------------
boxes = r.boxes
# 如果没有检测到任何目标,则直接退出
if boxes is None or len(boxes) == 0:
print("No objects detected.")
return
# Counter 用来统计“每个类别出现了多少次”
counts = Counter()
print(f"Detected {len(boxes)} objects:\n")
# enumerate(boxes, start=1):给每个框编号从 1 开始
for i, b in enumerate(boxes, start=1):
# -----------------------
# 6) 读取类别与置信度
# b.cls / b.conf 是 tensor,通常形状是 [1]
# 所以用 [0] 取出数值,再转成 int/float 方便打印
# -----------------------
cls_id = int(b.cls[0]) # 类别 id,例如 0
cls_name = names[cls_id] # 类别名,例如 'person'
conf = float(b.conf[0]) # 置信度,例如 0.87
# -----------------------
# 7) 读取边界框坐标
# xyxy:左上角(x1,y1) + 右下角(x2,y2)
# xywh:中心点(cx,cy) + 宽(w) + 高(h)
# 都是“像素坐标”,基于原图尺寸(不是归一化到 0-1)
# -----------------------
x1, y1, x2, y2 = map(float, b.xyxy[0])
cx, cy, w, h = map(float, b.xywh[0])
# 更新类别统计
counts[cls_name] += 1
# 打印当前检测框的信息
print(
f"[{i:02d}] {cls_name:>12s} conf={conf:.3f} "
f"xyxy=({x1:.1f},{y1:.1f},{x2:.1f},{y2:.1f}) "
f"xywh=({cx:.1f},{cy:.1f},{w:.1f},{h:.1f})"
)
# -----------------------
# 8) 打印统计结果(按出现次数从多到少排序)
# counts.most_common() 返回形如 [('person', 5), ('bus', 1), ...]
# -----------------------
print("\nCounts by class:")
for k, v in counts.most_common():
print(f" {k}: {v}")
# Python 脚本入口:直接运行该文件时会执行 main()
if __name__ == "__main__":
main()
我们关心的数据一般为:
r.boxes:所有检测框的集合。每个框 b 里包含:
b.cls:类别 id(tensor)
b.conf:置信度(tensor)
b.xyxy:边界框坐标(tensor)
b.xywh:另一种坐标表达(tensor)
2、接入摄像头进行识别
安装opencv相关
sudo apt update
sudo apt install -y python3-picamera2 python3-opencv
新建一个python代码,这部分是CSI摄像头
import time
import cv2
from picamera2 import Picamera2
from ultralytics import YOLO
# 1) 载入模型(先用轻量版,树莓派更容易跑起来)
model = YOLO("yolov8n.pt")
# 2) 初始化 Picamera2
picam2 = Picamera2()
# 为了速度,先用较小分辨率;后面你再调高
W, H = 640, 480
config = picam2.create_preview_configuration(main={"size": (W, H), "format": "RGB888"})
picam2.configure(config)
picam2.start()
# 3) 实时循环:取帧 -> YOLO -> 画框 -> 显示
win = "CSI + YOLO (press Q to quit)"
cv2.namedWindow(win, cv2.WINDOW_NORMAL)
conf = 0.25
imgsz = 640
stride = 2 # 每 stride 帧推理一次:2≈减半计算量。想更快就 3/4;想更密就 1
frame_id = 0 #给“采集到的每一帧”编号
infer_count = 0#记录“到目前为止,总共做了多少次推理(检测更新)”
last_annotated = None #缓存“上一次推理得到的带框图像”,用于在不推理的帧里复用。
start = time.perf_counter() #记录“整个程序统计的起点时间”。
frame_count = 0 #记录“循环跑了多少帧/显示了多少次”。
infer_time_sum = 0.0 # 累计推理耗时(只算predict+plot)
try:
while True:
frame_id += 1
frame_count += 1
# Picamera2 返回的是 RGB
rgb = picam2.capture_array()
do_infer = (frame_id % stride == 0)
if do_infer:
infer_count += 1
t_in0 = time.perf_counter()
results = model.predict(source=rgb, imgsz=imgsz, conf=conf, verbose=False)
last_annotated = results[0].plot() # 返回带框图(BGR)
t_in1 = time.perf_counter()
infer_time_sum += (t_in1 - t_in0)
show = last_annotated
else:
# 不推理的帧沿用上一次结果,保持“看起来流畅”
show = last_annotated if last_annotated is not None else rgb
cv2.imshow(win, show)
# 每 30 次推理打印一次推理 FPS(注意:不是摄像头 FPS)
if do_infer and infer_count % 30 == 0:
now = time.perf_counter()
avg_infer = infer_time_sum / 30.0
infer_only_fps = 1.0 / avg_infer
detect_hz = infer_count / (now - start) # 实际检测更新频率(受stride影响)
ui_fps = frame_count / (now - start) # 窗口刷新频率(体感流畅度)
print(
f"Avg infer {avg_infer*1000:.1f} ms ({infer_only_fps:.2f} FPS) | "
f"Detect rate {detect_hz:.2f} Hz | UI FPS {ui_fps:.1f} | stride={stride} imgsz={imgsz}"
)
infer_time_sum = 0.0
if (cv2.waitKey(1) & 0xFF) in (ord('q'), ord('Q')):
break
finally:
picam2.stop()
cv2.destroyAllWindows()
下面是USB摄像头版本代码
import time
import cv2
from ultralytics import YOLO
# 1) 载入模型(先用轻量版,树莓派更容易跑起来)
model = YOLO("yolov8n.pt")
# 2) 初始化 USB 摄像头(一般 0 就是 /dev/video0)
cam_index = 8
cap = cv2.VideoCapture(cam_index, cv2.CAP_V4L2)
# 可选:设置分辨率/帧率(不一定每个摄像头都支持,失败也不会报错)
W, H = 640, 480
cap.set(cv2.CAP_PROP_FRAME_WIDTH, W)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, H)
cap.set(cv2.CAP_PROP_FPS, 30)
if not cap.isOpened():
raise RuntimeError(f"Cannot open USB camera index {cam_index}. Try 0/1/2...")
# 3) 实时循环:取帧 -> YOLO -> 画框 -> 显示
win = "USB Cam + YOLO (press Q to quit)"
cv2.namedWindow(win, cv2.WINDOW_NORMAL)
conf = 0.25
imgsz = 640
stride = 2 # 每 stride 帧推理一次:2≈减半计算量。想更快就 3/4;想更密就 1
frame_id = 0 # 给“采集到的每一帧”编号
infer_count = 0 # 记录“到目前为止,总共做了多少次推理(检测更新)”
last_annotated = None # 缓存“上一次推理得到的带框图像”,用于在不推理的帧里复用。
start = time.perf_counter() # 记录“整个程序统计的起点时间”。
frame_count = 0 # 记录“循环跑了多少帧/显示了多少次”。
infer_time_sum = 0.0 # 累计推理耗时(只算 predict+plot)
try:
while True:
frame_id += 1
frame_count += 1
ok, frame = cap.read()
if not ok or frame is None:
# 读帧失败就跳过(也可以 break)
continue
# frame 是 BGR(OpenCV 默认)
do_infer = (frame_id % stride == 0)
if do_infer:
infer_count += 1
t_in0 = time.perf_counter()
results = model.predict(source=frame, imgsz=imgsz, conf=conf, verbose=False)
last_annotated = results[0].plot() # 带框图(通常是 BGR)
t_in1 = time.perf_counter()
infer_time_sum += (t_in1 - t_in0)
show = last_annotated
else:
# 不推理的帧沿用上一次结果,保持“看起来流畅”
show = last_annotated if last_annotated is not None else frame
cv2.imshow(win, show)
# 每 30 次推理打印一次推理 FPS(注意:不是摄像头 FPS)
if do_infer and infer_count % 30 == 0:
now = time.perf_counter()
avg_infer = infer_time_sum / 30.0
infer_only_fps = 1.0 / avg_infer
detect_hz = infer_count / (now - start) # 实际检测更新频率(受 stride 影响)
ui_fps = frame_count / (now - start) # 窗口刷新频率(体感流畅度)
print(
f"Avg infer {avg_infer*1000:.1f} ms ({infer_only_fps:.2f} FPS) | "
f"Detect rate {detect_hz:.2f} Hz | UI FPS {ui_fps:.1f} | stride={stride} imgsz={imgsz}"
)
infer_time_sum = 0.0
if (cv2.waitKey(1) & 0xFF) in (ord('q'), ord('Q')):
break
finally:
cap.release()
cv2.destroyAllWindows()
usb摄像头的编号是什么需要输入指令查看
v4l2-ctl --list-devices

例如我的树莓派上是视频口8.所以代码中cam_index = 8。
运行实时识别
使用在《树莓派5部署YOLO》一文中建好的虚拟环境
source ~/venv/bin/activate
python ~/yolodemo/csi_yolo_live.py
目前设置是stride=2 时,循环是这样的:
第 1 帧:推理(infer_count 变 1)
第 2 帧:不推理(infer_count 还是 1)
第 3 帧:推理(infer_count 变 2)
第 4 帧:不推理(infer_count 还是 2)
...
运行结果可以看到帧率在3帧不到,但是这里的帧不是视频输出的帧率概念,其实是推理频率的含义。视频刷新的帧率是UI FPS 大约在5.2帧。可以看出推理的时间大约在300ms以上,如果想要提高视频的刷新率可以提高stride的值,减少推理次数,但是推理的时间其实是不会变化太多的。接下来我们目标是减少推理时间,提高推理的帧率。

以上信息含义:
Avg infer:单次“推理流程”的平均耗时(单位毫秒)。取倒数就是推理理论帧率,不是图像刷新帧率
Detect rate:真实世界里,每秒实际完成了多少次“检测更新”(也就是执行了多少次 do_infer=True 的推理)。
UI FPS:窗口每秒刷新的帧数(循环跑了多少次、调用 imshow 显示了多少帧)。
3、改善推理时间,提高推理帧率
1)、可以减低推理图片的大小,修改imgsz=512,可以看出推理时间减少,推理帧率提高。但是随之带来的是检测范围的降低,这里需要按需求平衡。

2)、换推理后端(NCNN)
导出(从512 开始,可以和1)中结果对比):
yolo export model=yolov8n.pt format=ncnn imgsz=512
修改代码,将yolov8n.pt换成yolov8n_ncnn_model
model = YOLO("./yolov8n_ncnn_model")
运行代码后

上一节最后对比可以发现,推理时间从原来的300多ms减少到70多ms,推理帧率到了13帧以上,推理时间减少直接也提高了视频的刷新帧率。
此外修改imgsz大小,减少物品识别种类都可以提高推理帧率。此外还可以将推理和视频采集分开在两个进程中,采集和推理分开这样视频的刷新帧率可以很高视频更流畅。可以尝试对比。
 网站备案号:ICP备16046599号-1
网站备案号:ICP备16046599号-1