本篇文章由 VeriMake 旧版论坛中备份出的原帖的 Markdown 源码生成
原帖标题为:R 语言 | 因子与数据框
原帖网址为:https://verimake.com/topics/229 (旧版论坛网址,已失效)
原帖作者为:dawdler(旧版论坛 id = 64,注册于 2020-08-17 14:01:22)
原帖由作者初次发表于 2021-05-31 18:51:35,最后编辑于 2021-05-31 18:51:35(编辑时间可能不准确)
截至 2021-12-18 14:27:30 备份数据库时,原帖已获得 336 次浏览、0 个点赞、0 条回复
R 因子与数据框
1. 因子
在R语言中,因子被用来代表数据中分类的变量,比如性别、年龄、学历等,因此也被称为“类别变量”。值得注意的是,类似姓名这样每个人都不一样的特征一般不被看作不同类别,即使有两个人重名,这个重复的名字也不能代表两个人被分为同一类。简单来说,因子被用来表示一组数据中的类别,并记录这组数据中的类别名称以及类别数目。分数、天气污染指数等有序的类别可以设置is.ordered()来体现其有序性,也更方便其相关的操作。
R语言使用factor()函数来创建因子,并且使用向量作为输入参数。
factor(x = c(), levels, labels=levels, exclude=NA, ordered=is.ordered(x), nmax=NA)
举个例子:
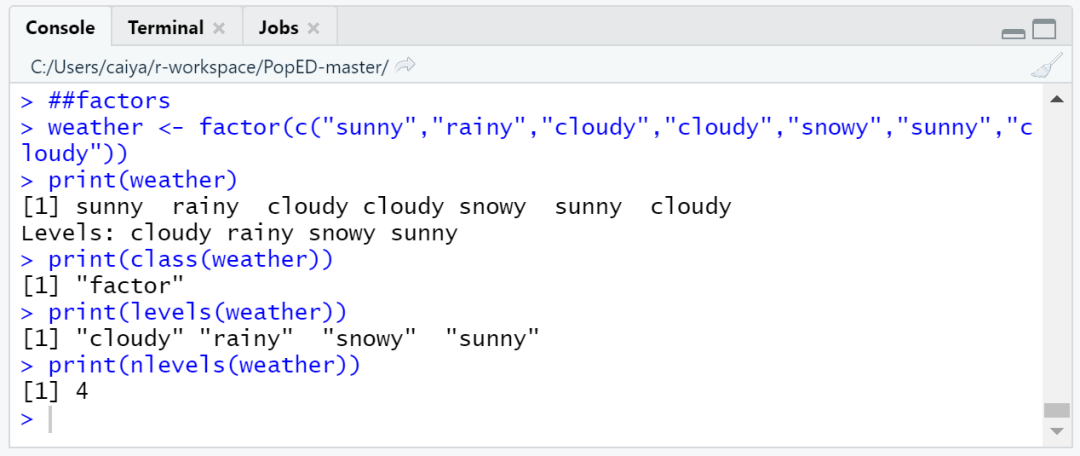
##factors
weather <- factor(c("sunny","rainy","cloudy","cloudy","snowy","sunny","cloudy"))
print(weather)
#weather的数据类型是“factor”因子
print(class(weather))
#levels()查看该因子中具体有哪些类别,也叫水平值
#在定义因子时如果没有指定levels,则自动根据因子中的不步的值生成
print(levels(weather))
#nlevels()查看一共有几个类别
print(nlevels(weather))
以上代码的输出结果为:
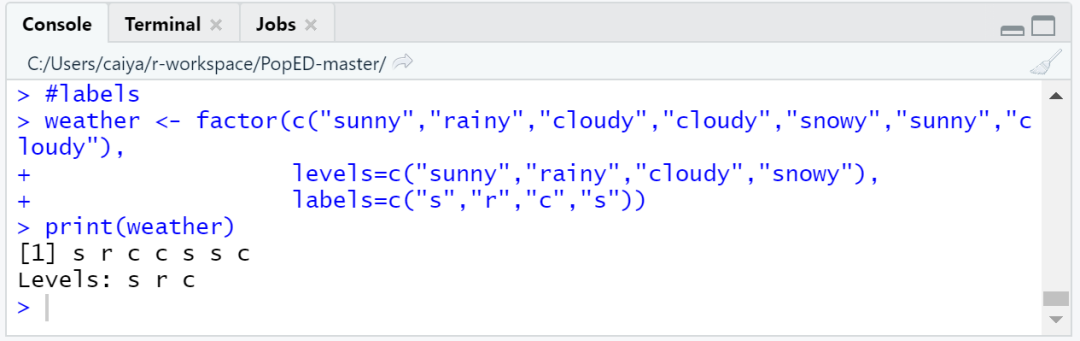
同同时,与我们可以为列表里的元素赋标签一样,因子的类别也可以被赋予标签。比如:
#labels
#levels代表原始类别名称,labels相当于给这些类别赋予了新的名字
#注意定义levels和labels时,顺序要一样哦
weather <- factor(c("sunny","rainy","cloudy","cloudy","snowy","sunny","cloudy"),
levels=c("sunny","rainy","cloudy","snowy"),
labels=c("s","r","c","s"))
print(weather)
图2
2. 数据框
2.1 什么是数据框
R语言中的数据框,即data frame,在形式上非常像表格,也是一种特殊的二维列表。数据框的每一列都有一个唯一的列名,并且长度相等,同一列的数据类型也要一直。(不同列的数据类型可以不同)
R语言使用data.frame()函数来创建数据框:
data.frame(... , row.names=NULL, check.rows=FALSE, check.names=TRUE, fix.empty.names=TRUE, stringsAsFactors=default.stringAsFactors())
其中,row.names被用来定义行名,默认为NULL;
check.rows被用来检测行的名称与长度是否符合要求;
fix.empty.names被用来设置未命名的参数是否制动设置名字;
stringsAsFactors被用来设置字符是否转换为因子,默认为TRUE。
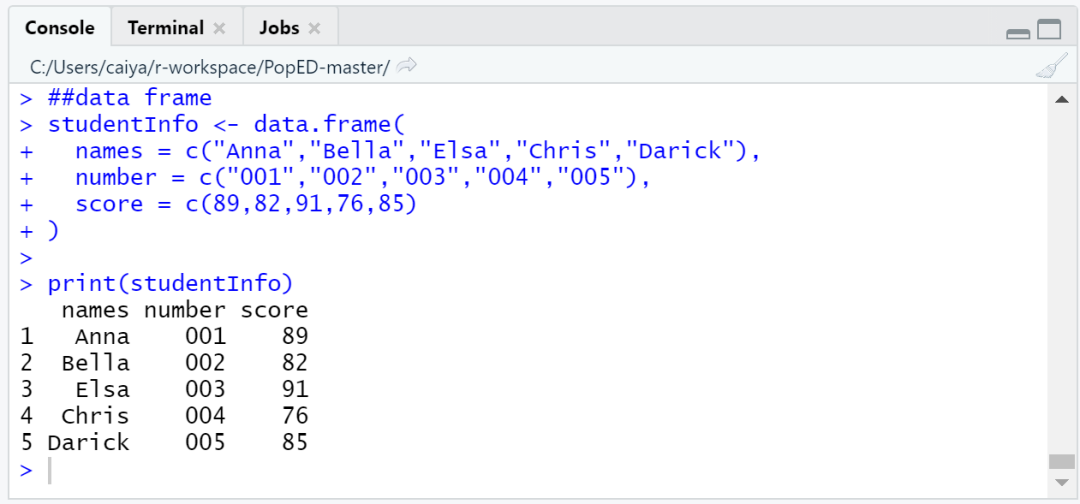
##data frame
studentInfo <- data.frame(
names = c("Anna","Bella","Elsa","Chris","Darick"),
number = c("001","002","003","004","005"),
score = c(89,82,91,76,85)
)
print(studentInfo)
#当然,我们也可以直接调用cbind(vector1,vector2,...)函数直接将向量合并为数据框
以上代码的输出结果为:
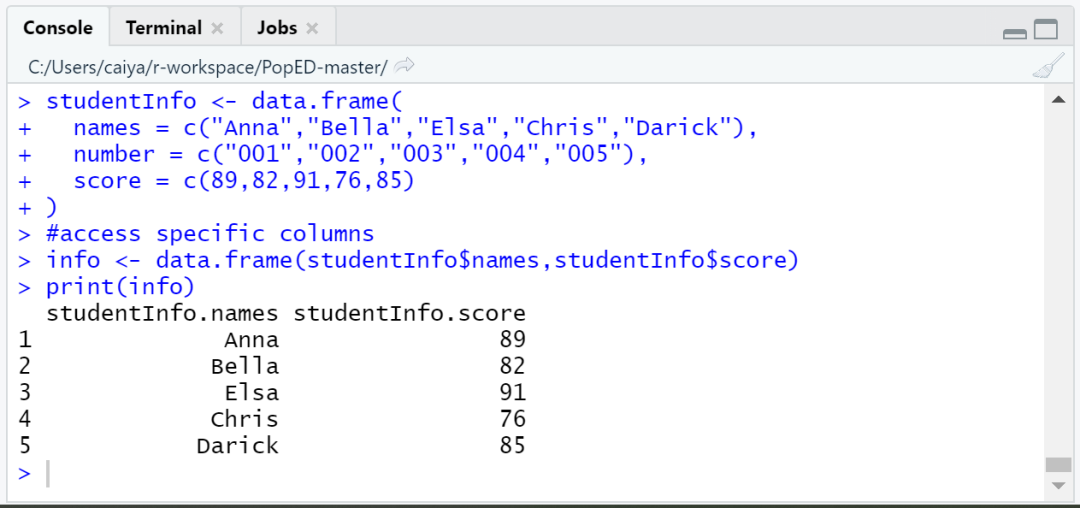
2. 2数据框的访问
##data frame
studentInfo <- data.frame(
names = c("Anna","Bella","Elsa","Chris","Darick"),
number = c("001","002","003","004","005"),
score = c(89,82,91,76,85)
)
#access specific columns
info <- data.frame(studentInfo$names,studentInfo$score)
print(info)
#除了通过列名访问,通过列的位置访问,比如studentInfo[,1:2]
以上代码的输出结果为:
除了访问特定的列,我们也可以访问特定的行:
##data frame
studentInfo <- data.frame(
names = c("Anna","Bella","Elsa","Chris","Darick"),
number = c("001","002","003","004","005"),
score = c(89,82,91,76,85)
)
#access specific rows
#first 2 rows
info <- data.frame(studentInfo[1:2,])
print(info)
#如果定义了行名,也可以通过行名访问
以上代码的输出结果为:
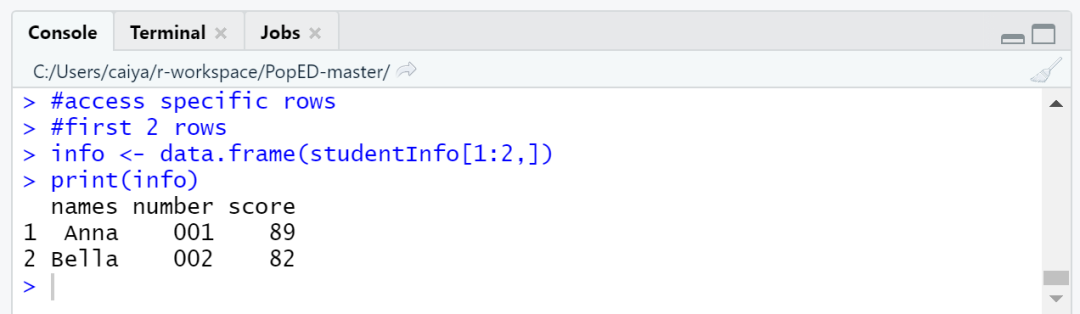
当然,如果不想完整提取行列,比如我们只想读取第2、3行中第1、2列的数据,可以studentInfo[c(2,3),c(1,2)]
2.3 扩展数据框
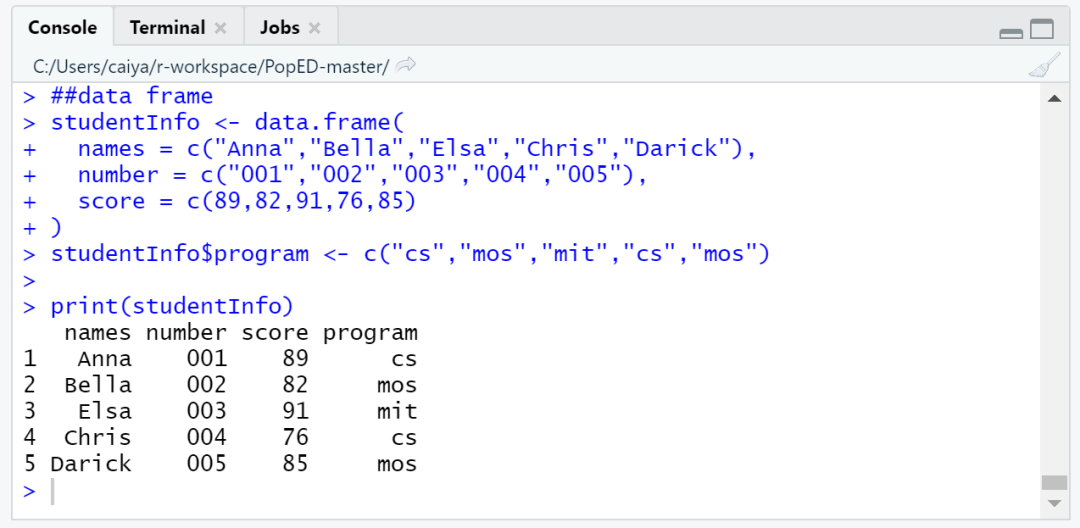
对于已有的数据框,如果我们想要增加新的列,可以直接使用table$col.name <- c(...)的语句添加。
##data frame
studentInfo <- data.frame(
names = c("Anna","Bella","Elsa","Chris","Darick"),
number = c("001","002","003","004","005"),
score = c(89,82,91,76,85)
)
studentInfo$program <- c("cs","mos","mit","cs","mos")
print(studentInfo)
#将两个现有的数据框合并可以使用rbind(table1,table2,...)函数
以上代码的输出结果为:
2.4 输出总结信息
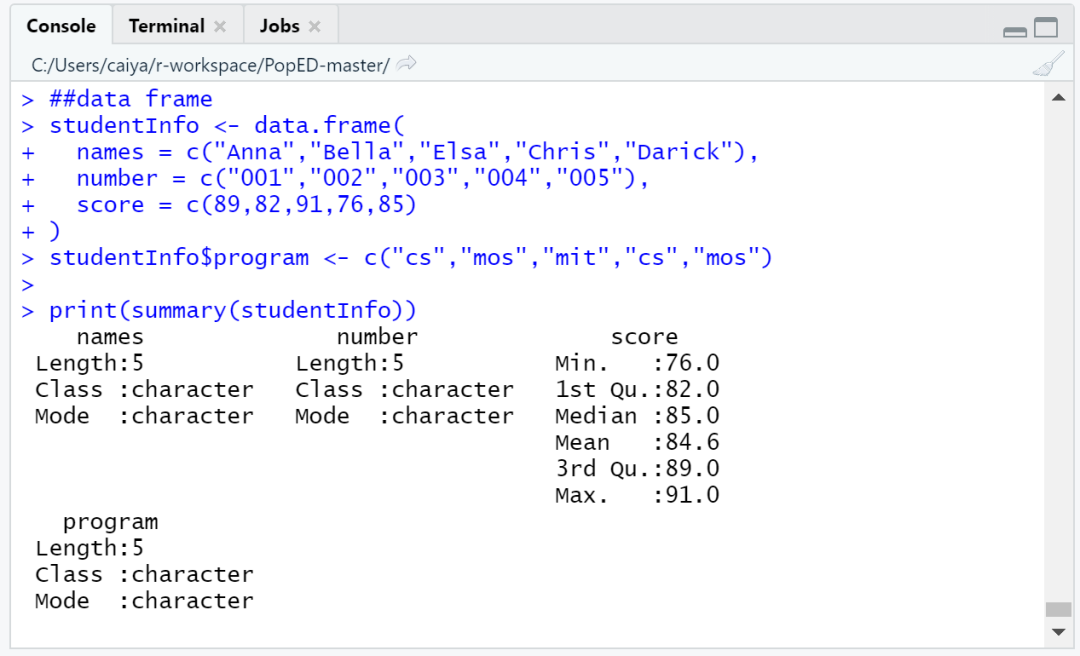
除了直接输出数据框本身,R语言还提供了一个输出概要信息的函数summary(),对于内容数字型的列,会自动计算出最小值、最大值、中位数、平均数等具备统计学意义的参数。
##data frame
studentInfo <- data.frame(
names = c("Anna","Bella","Elsa","Chris","Darick"),
number = c("001","002","003","004","005"),
score = c(89,82,91,76,85)
)
studentInfo$program <- c("cs","mos","mit","cs","mos")
print(summary(studentInfo))
以上代码的输出结果为:
相关资料:
https://www.runoob.com/r/r-factor.html
https://www.runoob.com/r/r-data-frame.html
 网站备案号:ICP备16046599号-1
网站备案号:ICP备16046599号-1